
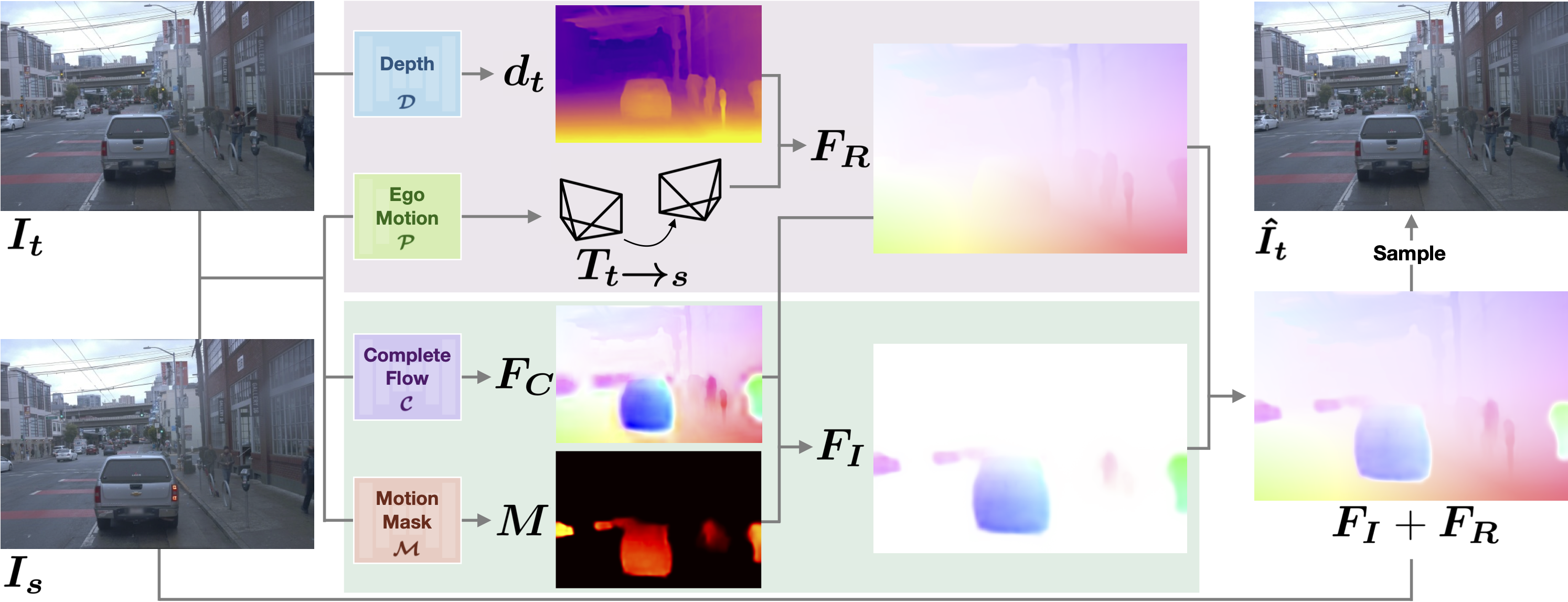
Unsupervised monocular depth estimation techniques have demonstrated encouraging results but typically assume that the scene is static. These techniques suffer when trained on dynamical scenes, where apparent object motion can equally be explained by hypothesizing the object's independent motion, or by altering its depth. This ambiguity causes depth estimators to predict erroneous depth for moving objects.
To resolve this issue, we introduce Dynamo-Depth, an unifying approach that disambiguates dynamical motion by jointly learning monocular depth, 3D independent flow field, and motion segmentation from unlabeled monocular videos. Specifically, we offer our key insight that a good initial estimation of motion segmentation is sufficient for jointly learning depth and independent motion despite the fundamental underlying ambiguity. Our proposed method achieves state-of-the-art performance on monocular depth estimation on Waymo Open and nuScenes Dataset with significant improvement in the depth of moving objects.
@article{sun2024dynamo,
title={Dynamo-depth: fixing unsupervised depth estimation for dynamical scenes},
author={Sun, Yihong and Hariharan, Bharath},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}